The Book
Some things in Nanos are set in stone and others are not. In general security and performance are top of mind and we abide by KISS principles.
Quick FYI: This site is mainly for Nanos specific
information. If you are an end-user and you just want more "getting
started" docs please check out the DOCS on OPS.CITY which are substantial.
This site is a WIP
(work in progress).
Filesystem
The filesystem currently used by Nanos is TFS. Nanos isn't opposed to other file systems but hasn't
identified a large need yet either. As with most of these sections if your team requires different
filesystem support please reach out to the NanoVMs team for a support subscription.
For more info on the TFS
filesystem.
Nanos supports the following storage drivers:
virtio_blk
virtio_scsi
pvscsi
nvme
ata_pci
storvsc
xenblk
Storvsc is used on Hyper-v/Azure. The drivers virtio_blk and virtio_scsi are used in QEMU/KVM cloud-based like AWS, GCE, Vultr, Digital Ocean and Oracle cloud. The xenblk driver supports the xenblk device in Xen. The ata_pci driver is supported in QEMU/KVM. The pvscsi, which is the driver for VMware paravirtualized scsi devices, is used in ESX instances. The driver for nvme can be used in clouds like GCE, AWS, Digital Ocean and Vultr.
Networking
Nanos supports both IPV4 and IPV6. For more information on configuring things like VPCs, firewalls and the like please consult the OPS networking config pages for your specific cloud.
Performance
Requests/Second
Not a lot of benchmarking and tuning has been done yet, however, there is plenty of potential. Currently, our naive tests can push 2X the amount of requests/second for Go webservers. This website is hosted on a Go webserver running a recent 0.1.27 version of Nanos. We've also seen up to 3X improvements on AWS.
Boot Time
Using the method described here with an un-stripped kernel we are seeing boot times of ~195ms from top of MBR bootloader to userspace frame return. However if you use a stripped kernel we can see 72ms. It should be noted that both infrastructure provider and application payload are going to significantly alter your boot time. For instance booting under firecracker with your own hardware is going to vastly out-perform booting on Azure. Likewise, booting a small c webserver is going to be much faster than booting a full blown Rails or JVM application. In short, the biggger the filesystem payload expect to pay more in boot time.Minimum Memory Utilization
Currently the minimum memory utilization we have seen operate under the following conditions:| Qemu: | C 26 MB | Go 40 MB | Firecracker: | C 24 MB | Go 37 MB | VirtualBox: | C 24 MB | Go 36 MB |
Security
Nanos has an opionated view of security. Users and their associated permissions are not supported. Nanos is
also a single process (but multi-threaded) system. This means there is no support for SSH, shells or any
other interactive multiple command/program running. While this prevents quite a few security issues extra
precaution should be taken for things such as RFI style attacks. For instance you wouldn't want to leak your
SSL private key or database credentials.
Similarily, just cause you can't create a new process
doesn't mean an attacker couldn't inject their process.
Nanos employs various forms of security
measures found in other general purpose operating systems including ASLR and respects page protections that
compilers produce.
Nanos, unlike other general purpose operating systems, only provision what is
necessary on the filesystem to run an application so most filesystems will have a few to maybe 10 libraries
and many applications might have filesystems with only a handful of files on them.
Nanos's kernel
lives on a different partition and is separated from the user-viewable partition. Nanos goes further with
the idea of exec protection with an optional exec_protection flag available in the manifest. When this is
enabled the application cannot modify the executable files and cannot create new executable files. For
further information check out this PR.
For
more info: more info

Nanos reduces its attack surface through a variety of
thrusts. Compared to a normal Ubuntu or Debian instance has multiple
orders of magnitude less lines of code, libraries only that are needed
by an application and thousands of less executables - in fact it only
can run one.
Nanos employs the following:
ASLR:
- Stack Randomization
- Heap Randomization
- Library Randomization
- Binary Randomization
Page Protections:
- Stack Execution off by Default
- Heap Execution off by Default
- Null Page is Not Mapped
- Stack Cookies/Canaries
- Rodata no execute
- Text no write
Architecture-level Security Technologies:
- Supervisor Mode Execution Protection (SMEP)
- User Mode Instruction Prevention (UMIP)
In addition to storing global constants in read-only pages at link time, Nanos gathers globals that should only be set at initialization time and stores them in a special section. The pages of this section are then rendered immutable after initialization is complete.
Code pages in Nanos have writes disabled, and execution of code in stack pages is forbidden. In the few cases that Nanos generates executable instructions (for vdso and vsyscall use), such code is similarly protected from writes. Closures do not contain jumps or other executable instructions.
Nanos has an 'exec protection' feature that prevents the kernel from executing any code outside the main executable and other 'trusted' files explicitly marked. The program is further limited from modifying the executable file and creating new ones. This flag may also be used on individual files within the children tuple. This prevents the application from exec-mapping anything that is not explicitly mapped as executable. This is not on by default, however, as many JITs won't work with it turned on. You can turn this on via the ops flag:
{
"ManifestPassthrough": {
"exec_protection": "t"
}
}Architecture
Currently Nanos supports X86-64, ARM64 (specifically for rpi4, graviton 2/3 instances and has SMP) and has limited RISC-V support.
The POWER family of architectures have been asked for but so far there is no roadmap for it. If you are interested in getting that sooner reach out to the NanoVMs team.
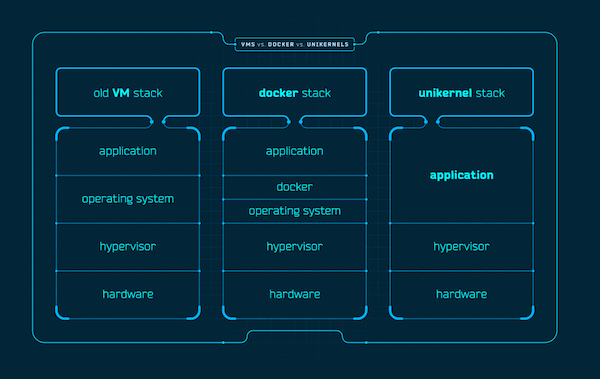
Nanos is always deployed as a guest VM directly on top of a
hypervisor. Unlike Linux that runs many different applications on top of
it Nanos molds the system and application into one discrete unit. Unlike
Containers that duplicate storage and networking layers with an
orchestrator in between Linux and the application Nanos relies on the
native storage and networking layers present in the hypervisor of
choice.
Infrastructure
Thread scheduling in Nanos is not cooperative but pre-emptive. CPU-bound threads with long running computations are preempted by the kernel in order not to starve other threads.
Any event that generates an interrupt on a given CPU causes the thread running on that CPU to be preempted, at which point the kernel event loop processes the event and then resumes one of the threads ready to run (which may or may not be the same thread that was just preempted, depending on how much CPU time each thread has used). The kernel makes sure that a hardware timer is always armed on a CPU before running a thread on that CPU, so that the thread is guaranteed to be preempted if it runs "for too long".
When a thread yields, nothing special happens; the kernel just re-evaluates the list of threads ready to run and then resumes one of them, in much the same way as done when a thread has been preempted.
A scheduling algorithm assigns CPU resources to a task based on how much CPU time the task used in the past. It uses a priority queue where tasks are ordered based on their CPU time: when a task is enqueued, it is positioned according to the time it has been running since it was last scheduled; when a task is dequeued, its CPU time is subtracted from the CPU time of any other tasks in the queue, so that their priority in the queue is increased. This is implemented by storing a reference CPU time in the queue (min_runtime struct member), which prevents long-running tasks from being starved by newly created tasks. This algorithm is applied for scheduling user threads, so that CPU time is distributed fairly between all runnable threads.
Nanos can currently deploy to the following public cloud providers:
→ Google Cloud
→ Amazon Web Services
→ Digital Ocean
→ Vultr
→ Microsoft Azure
→ Hetzner
→ Scaleway
→ Oracle Cloud
→ UpCloud
→ OpenStack
→ ProxMox
Nanos can also deploy to the following hypervisors:
→ KVM
→ Xen
Bhyve
→ ESX
FireCracker
VirtualBox
→ Hyper-V
Nanos can even run on
K8S.
Syscalls
Supported:
socket bind listen accept accept4 connect sendto sendmsg sendmmsg recvfrom recvmsg setsockopt getsockname getpeername getsockopt shutdown futex clone arch_prctl set_tid_address gettid timerfd_create timerfd_gettime timerfd_settime timer_create timer_settime timer_gettime timer_getoverrun timer_delete getitimer setitimer alarm mincore mmap mremap msync munmap mprotect epoll_create epoll_create1 epoll_ctl poll ppoll select pselect6 epoll_wait epoll_pwait read pread64 write pwrite64 open openat dup dup2 dup3 fstat fallocate fadvise64 sendfile stat lstat readv writev truncate ftruncate fdatasync fsync sync syncfs io_setup io_submit io_getevents io_destroy access lseek fcntl ioctl getcwd symlink symlinkat readlink readlinkat unlink unlinkat rmdir rename renameat renameat2 close sched_yield brk uname getrlimit setrlimit prlimit64 getrusage getpid exit_group exit getdents getdents64 mkdir mkdirat getrandom pipe pipe2 socketpair eventfd eventfd2 creat chdir fchdir utime utimes newfstatat sched_getaffinity sched_setaffinity capget prctl sysinfo umask statfs fstatfs io_uring_setup io_uring_enter io_uring_register kill pause rt_sigaction rt_sigpending rt_sigprocmask rt_sigqueueinfo rt_tgsigqueueinfo rt_sigreturn rt_sigsuspend rt_sigtimedwait sigaltstack signalfd signalfd4 tgkill tkill clock_gettime clock_nanosleep gettimeofday nanosleep time times inotify_init inotify_add_watch inotify_rm_watch inotify_init1
unsupported:
shmget shmat shmctl fork vfork execve wait4, syscall_ignore); semget semop semctl shmdt msgget msgsnd msgrcv msgctl flock, syscall_ignore); link chmod, syscall_ignore); fchmod, syscall_ignore); fchown, syscall_ignore); lchown, syscall_ignore); ptrace syslog getgid, syscall_ignore); getegid, syscall_ignore); setpgid getppid getpgrp setsid setreuid setregid getgroups setresuid getresuid setresgid getresgid getpgid setfsuid setfsgid getsid mknod uselib personality ustat sysfs getpriority setpriority sched_setparam sched_getparam sched_setscheduler sched_getscheduler sched_get_priority_max sched_get_priority_min sched_rr_get_interval mlock, syscall_ignore); munlock, syscall_ignore); mlockall, syscall_ignore); munlockall, syscall_ignore); vhangup modify_ldt pivot_root _sysctl adjtimex chroot acct settimeofday mount umount2 swapon swapoff reboot sethostname setdomainname iopl ioperm create_module init_module delete_module get_kernel_syms query_module quotactl nfsservctl getpmsg putpmsg afs_syscall tuxcall security readahead setxattr lsetxattr fsetxattr getxattr lgetxattr fgetxattr listxattr llistxattr flistxattr removexattr lremovexattr fremovexattr set_thread_area io_cancel get_thread_area lookup_dcookie epoll_ctl_old epoll_wait_old remap_file_pages restart_syscall semtimedop clock_settime vserver mbind set_mempolicy get_mempolicy mq_open mq_unlink mq_timedsend mq_timedreceive mq_notify mq_getsetattr kexec_load waitid add_key request_key keyctl ioprio_set ioprio_get migrate_pages mknodat fchownat, syscall_ignore); futimesat linkat fchmodat, syscall_ignore); faccessat unshare set_robust_list get_robust_list splice tee sync_file_range vmsplice move_pages utimensat preadv pwritev perf_event_open recvmmsg fanotify_init fanotify_mark name_to_handle_at open_by_handle_at clock_adjtime setns getcpu process_vm_readv process_vm_writev kcmp finit_module sched_setattr sched_getattr seccomp memfd_create kexec_file_load bpf execveat userfaultfd membarrier mlock2, syscall_ignore); copy_file_range preadv2 pwritev2 pkey_mprotect pkey_alloc pkey_free
Features
→ -d strace
→ ftrace
→ http server dump
Tools
Several tools are packaged inside Nanos: mkfs
➜ ~ ~/.ops/0.1.27/mkfs -help
/Users/eyberg/.ops/0.1.27/mkfs: illegal option -- h
Usage:
mkfs [options] image-file < manifest-file
mkfs [options] -e image-file
Options:
-b boot-image - specify boot image to prepend
-k kern-image - specify kernel image
-r target-root - specify target root
-s image-size - specify minimum image file size; can be expressed in
bytes, KB (with k or K suffix), MB (with m or M suffix), and GB (with g
or G suffix)
-e - create empty filesystemdump
➜ ~ ~/.ops/0.1.27/dump
Usage: dump [OPTION]...
Options:
-d Copy filesystem contents from into
-t Display filesystem from as a tree IntelliJ
Manifest
The nanos manifest is an extremely powerful tool as it comes with many different flags and is the synthesis
of a filesystem merged with various settings. Most users will never craft their own manifests by hand,
opting to use OPS to craft it automatically.
→ futex_trace
→ debugsyscalls
→ fault
→
exec_protect
Data Structures
Nanos uses a variety of internal data structures. This is only a partial list.
- Bitmap
- ID Heap
- FreeList
- Backed Heap
- Linear Backed Heap
- Paged Back Heap
- Priority Queue
- RangeMap
- Red/Black Tree
- Scatter/Gather List
- Table
- Tuple
Bitmaps
A bitmap is an array of bits to store binary variables. A bitmap is represented with the struct bitmap (see bitmap.h):
typedef struct bitmap {
u64 maxbits;
u64 mapbits;
heap meta;
heap map;
buffer alloc_map;
} *bitmap;- maxbits is the number of bits that the bitmap contains
- mapbits is the number of bits that has been allocated for this bitmap which is rounded up to the nearest 64 bits
- meta is the heap to allocate the bitmap structure
- map is the heap to allocate the bitmap buffer
- alloc_map is the buffer that contains the actual bitmap
The bitmap length may be arbitrarily sized. The bitmap buffer is allocated in ALLOC_EXTEND_BITS / 8 byte increments as needed. In the following, we present the functions that manipulate bitmaps.
Instantiation
allocate_bitmap allocates and initializes a bitmap structures. The function is defined as follows:
bitmap allocate_bitmap(heap meta, heap map, u64 length)
{
bitmap b = allocate_bitmap_internal(meta, length);
if (b == INVALID_ADDRESS)
return b;
u64 mapbytes = b->mapbits >> 3;
b->map = map;
b->alloc_map = allocate_buffer(map, mapbytes);
if (b->alloc_map == INVALID_ADDRESS)
return INVALID_ADDRESS;
zero(bitmap_base(b), mapbytes);
buffer_produce(b->alloc_map, mapbytes);
return b;
}This function begins by allocating the memory for the bitmap structure by using the heap at meta. This is done by the function allocate_bitmap_internal. The function initializes the heap used by the bitmap to meta. It sets mapbits to lenght by padding to the nearest 64 bit multiple. mapbits can't be greater than ALLOC_EXTEND_BITS or 4096 bits. maxbits is initialized to lenght. The function allocates the memory for the actual bitmap. At line 6, mapbytes contains the size of the bitmap in bytes. In line 8, the function allocate_buffer gets a buffer of size mapbytes. In line 11, this chunk is filling with zeros, and in line 12, the buffer is created. This is needed because the buffer buffer structure tracks the start and end points of the data in the allocated memory. While allocate_buffer allocates the required memory, buffer_produce moves the end pointer to mark that memory as used by the buffer and not available to grow into. Note that the allocation of a bitmap relies on different memory allocators (heaps) optimized for different tasks. One heap is using for metadata, i.e., meta, and one for data, i.e., map. If success, the function returns a pointer to a bitmap structure; otherwise, it returns INVALID_ADDRESS.
bitmap bitmap_clone(bitmap b)bitmap_clone can be used to allocate a new bitmap from an existing one. The function returns a bitmap which is a copy of the bitmap at b.
To release a bitmap, the caller uses the function deallocate_bitmap, which is defined as follows:
void deallocate_bitmap(bitmap b)
{
if (b->alloc_map)
deallocate_buffer(b->alloc_map);
deallocate(b->meta, b, sizeof(struct bitmap));
}The function first releases the buffer that contains the bitmap, and then, it releases the bitmap structure.
bitmap bitmap_wrap(heap h, u64 * map, u64 length)
void bitmap_unwrap(bitmap b)bitmap_wrap creates a bitmap structure from an already existing bitmap. This function reuses the bitmap at map so no allocation of a new bitmap is required.
bitmap_unwrap releases the wrapped buffer by releasing the buffer structure and the bitmap structure.
Accessors
u64 bitmap_alloc(bitmap b, u64 size);
u64 bitmap_alloc_within_range(bitmap b, u64 nbits, u64 start, u64 end);bitmap_alloc searches a bitmap for a range of nbits consecutive bits that are all cleared, and if such a range is found, sets all bits in the range and returns the first bit of the range; if not found, returns INVALID_PHYSICAL. The function bitmap_alloc_within_range behaves similarly than bitmap_alloc but it takes as parameter a range in which the region is searched.
boolean bitmap_dealloc(bitmap b, u64 bit, u64 size);bitmap_dealloc checks that the range of size bits starting from bit is set in the bitmap b; if this is true, the function clears all the bits in that range and returns true, otherwise it returns false.
static inline void bitmap_set(bitmap b, u64 i, int val);
static inline void bitmap_set_atomic(bitmap b, u64 i, int val);
static inline int bitmap_test_and_set_atomic(bitmap b, u64 i, int val);bitmap_set changes the value of the ith bit in the bitmap b depending on the value of val. If val is greater than zero, the bit is set; otherwise, the bit is cleared. The function bitmap_set_atomic sets a bit by using atomic operations. bitmap_test_and_set_atomic set or clear a bit depending on val. If true, the bit at i is set; otherwise, the bit is clear. This function is atomic.
static inline boolean bitmap_get(bitmap b, u64 i);bitmap_get returns the value of the i bit from the bitmap b. The following macros are used to iterate over the elements of a bitmap:
#define bitmap_foreach_word(b, w, offset) \
for (u64 offset = 0, * __wp = bitmap_base(b), w = *__wp; \
offset < (b)->mapbits; offset += 64, w = *++__wp)
#define bitmap_word_foreach_set(w, bit, i, offset) \
for (u64 __w = (w), bit = lsb(__w), i = (offset) + (bit); __w; \
__w &= ~(1ull << (bit)), bit = lsb(__w), i = (offset) + (bit))
#define bitmap_foreach_set(b, i) \
bitmap_foreach_word((b), _w, s) bitmap_word_foreach_set(_w, __bit, (i), s)The macro bitmap_foreach_word is used to walk a bitmap in 64 bits chunks by starting from offset. The macro bitmap_word_foreach_set is used to walk a chunk of 64 bits. The macro bitmap_foreach_set is used to walk a bitmap. For example, the following code uses bitmap_foreach_set to walk the bitmap and checks if it has been correctly initialized:
bitmap b = allocate_bitmap(h, h, 4096);
bitmap_foreach_set(b, i) {
if (i) {
msg_err("!!! allocation failed for bitmap\n");
return NULL;
}
}void bitmap_copy(bitmap dest, bitmap src)bitmap_copy copies the bitmap at src into the bitmap at dest. In case src is larger than dst, i.e., src.maxbits > dst.maxbits, dst is extended. The extended bits are cleared.
boolean bitmap_range_check_and_set(bitmap b, u64 start, u64 nbits, boolean validate, boolean set);bitmap_range_check_and_set sets a number of nbits by starting from start with the value at set. if validate is true, the function checks whether all bits in the supplied bit range are cleared in the bitmap before attempting to set them; otherwise, this check is skipped and the bits are set regardless of whether they were already set.
u64 bitmap_range_get_first(bitmap b, u64 start, u64 nbits)bitmap_range_get_first returns the first bit set in a given range, or INVALID_PHYSICAL if no bits are set.
Red/Black Trees
A rbtree (see rbtree.h) is represented with the following structure:
typedef struct rbtree {
rbnode root;
u64 count;
rb_key_compare key_compare;
rbnode_handler print_key;
heap h;
} *rbtree- root is a pointer to the root node of tree
- count is a counter of the number of nodes in the tree
- print_key is a function to print nodes
- key_compare is the comparator function to compare nodes
- head h is the heap to allocate the nodes
Each node in a rbtree is defined as follows:
typedef struct rbnode *rbnode;
struct rbnode {
word parent_color; /* parent used for verification */
rbnode c[2];
};
- parent_color is the color of the parent
- c[2] is an array of rbnodes that identifies each child
The color of a node is defines as follows:
#define black 0
#define red 1Instantiation
Rbtrees are instantiated by using the function allocate_rbtree():
rbtree allocate_rbtree(heap h, rb_key_compare key_compare, rbnode_handler print_key);The function returns a pointer to a new rbtree. When defining a new rbtree, we require to define the comparator function, e.g., thread_tid_compare, and the function to print keys, e.g., tid_print_key. For example, the following code shows the creation of the rbtree that keeps all the threads of the system:
p->threads = allocate_rbtree(h, closure(h, thread_tid_compare), closure(h, tid_print_key)We use the macros closure and closure_function for the definition of the functions:
closure_function(0, 2, int, thread_tid_compare,
rbnode, a, rbnode, b)
{
thread ta = struct_from_field(a, thread, n);
thread tb = struct_from_field(b, thread, n);
return ta->tid == tb->tid ? 0 : (ta->tid < tb->tid ? -1 : 1);
}
closure_function(0, 1, boolean, tid_print_key,
rbnode, n)
{
rprintf(" %!d(MISSING)", struct_from_field(n, thread, n)->tid);
return true;
}A rbtree can be initialized by using the function init_rbtree():
void init_rbtree(rbtree t, rb_key_compare key_compare, rbnode_handler print_key);This function is used in the same way than allocate_rbtree():
init_rbtree(&rm->t, closure(h, rmnode_compare), closure(h, print_key));Accesors
The insertion of a node is done by the function rbtree_insert_node():
boolean rbtree_insert_node(rbtree t, rbnode n);This function returns true if the rbtree has no root node so node is inserted in the root position; it returns false otherwise. The insertion of a node is based on the the comparator function. The traverse of a rbtree is done by the function rbtree_traverse():
#define RB_INORDER 0
#define RB_PREORDER 1
#define RB_POSTORDER 2
boolean rbtree_traverse(rbtree t, int order, rbnode_handler rh);This function takes as parameters the rbtree to traverse, the order in which the rbtree is traversed, e.g., INORDER, and the function called for each node. The function rbtree_lookup() is used to look for a node. The function uses the comparator over all the tree's nodes to compare with the rbnode k.
rbnode rbtree_lookup(rbtree t, rbnode k);If success, the function returns a pointer to a node; or INVALID_ADDRESS otherwise. The function rbtree_remove_by_key() is used to remove a node by a key:
boolean rbtree_remove_by_key(rbtree t, rbnode k);When success, the function returns true; or false otherwise. The function rbtree_dump() is used to dump a tree. The function is defined as follows:
void rbtree_dump(rbtree t, int order);The function gets as parameters the rbtree and the order in which the tree is traversed. The function remove_min() allows to get the node with the minimum key:
static rbnode remove_min(rbnode h, rbnode *removed)The functions rbnode_get_prev() and rbnode_get_next() are meant to get the next and the previous node from a given key:
rbnode rbnode_get_prev(rbnode h);
rbnode rbnode_get_next(rbnode h);These functions return INVALID_ADDRESS when the node is not found.
Releasing
The function destruct_rbtree() is used to release each node in a rbtree. The function is defined as follows:
void destruct_rbtree(rbtree t, rbnode_handler destructor);The rbtree is traversed and the destructor is called for each node. The function resets the root node of the rbtree. The function does not release the rbtree itself. The function deallocate_rbtree() is used to release all the nodes and the rbtree. This function is defined as follows:
void deallocate_rbtree(rbtree rb, rbnode_handler destructor);The function first call destruct_rbtree() and then it releases the rbtree structure.
ID Heap
Nanos allows developers to define different memory allocators named heaps optimized for different tasks. Rather than having a couple of heap allocation functions like Linux's kmalloc or vmalloc, Nanos uses a heap interface with allocate and deallocate function pointers that can be different for each heap structure. This results in a very flexible memory allocation. Developers can create hierarchies of heaps, or trivially change one heap to a special debug heap to help with troubleshooting. This section presents the API to manipulate Id Heaps (see id.h). These are general purpose allocators that carve up number space from a set of ranges that may be specified on initialization.
Instantiation
To create an Id heap, we use the function create_id_heap():
id_heap create_id_heap(heap meta, heap map, u64 base, u64 length, bytes pagesize, boolean locking);
- meta is the heap to allocate the metadata for the new heap
- map is the heap to allocate a bitmap to store the used elements
- base is the starting address of the chunk that is allocated
- length is the size of the chunk that is allocated
- pagesize is the minimum size of the allocations
- locking is a boolean variable that indicates that the heap may be accessed concurrently so accesses must be protected by using locking mechanisms
The function returns an id_heap that can be used to allocate chunks of memory by using the function allocate():
void * addr = allocate(id, PAGE_SIZE);This returns a pointer to a chunk of memory of PAGE_SIZE size. The size of the allocation must be greater or equal to the page size that is defined when the heap is created. This is not to be confused with the system page size, although allocators meant to serve allocations in page-sized units do indeed have a pagesize value equivalent to the system page size.
The function create_id_heap_backed() allows developers to create hierarchical heaps:
id_heap create_id_heap_backed(heap meta, heap map, heap parent, bytes pagesize, boolean locking)The function requires the heap parent argument from which the new heap goes to allocate new ranges of address space with allocations being a minimum of the parent heap page size.
Releasing
To de-allocate a chunk of memory, we use the deallocate() function:
deallocate(id, addr, PAGE_SIZE);We use the function named destroy_heap(id) to release all the resources allocated by the heap.
Page-backed Heap
The page-backed heap allocates in page-size units (see here). A page-backed heap is represented with the page_backed_page structure:
typedef struct page_backed_heap {
struct backed_heap bh;
heap physical;
heap virtual;
struct spinlock lock;
} *page_backed_heap;
Each address space is represented with a different heap: the physical and the virtual heap. The function allocates from both heaps an creates a mapping between them. The page-backed heap is required for individual pages that need different protection flags or otherwise need to have mappings manipulated for some reason.
Instantiation
The instantiation of a page_backed heap is done by the function:
backed_heap allocate_page_backed_heap(heap meta, heap virtual, heap physical, u64 pagesize, boolean locking)The function takes three heaps as arguments: one for the meta, one for the virtual address and one for the physical. In this heap, the pagesize corresponds with the page-size units of the architecture.
The page_backed_alloc_map() function is used to allocate a number of bytes from the page-backed heap:
static inline void *page_backed_alloc_map(backed_heap bh, bytes len, u64 *phys)The number of bytes in len are allocated from both heaps. The function also maps the physical address into the virtual address. In phys, It returns the pointer to the physical address. The function returns a pointer to the virtual address.
The page_backed_alloc_map_locking() function is used when mutual exclusion is required during allocation. The function is declared as follows:
void *page_backed_alloc_map_locking(backed_heap bh, bytes len, u64 *phys)Releasing
The page_backed_dealloc() function is used for the deallocation. It is based on page_backed_dealloc_unmap() for the unmapping between the virtual and the physical address. The function is declared as follows:
void page_backed_dealloc(heap h, u64 x, bytes length)When mutual exclusion is required during deallocation, developers can use the page_backed_dealloc_locking() function:
static void page_backed_dealloc_locking(heap h, u64 x, bytes length)Linear-backed Heap
The linear-backed heap takes advantage of the largest available pagesize on the architecture. The heap maps all physical memory that is allocated and thus memory can be accessed through the linear mapping without the need to set up a mapping for each allocation. A linear-backed heap is represented with the linear_backed_page structure (see here):
typedef struct linear_backed_heap {
struct backed_heap bh;
heap meta;
id_heap physical;
bitmap mapped;
} *linear_backed_heap;
The physical is the id heap from where the physical chunks are allocated.
Instantiation
The instantiation of a linear-backed heap is done by using the allocate_linear_backed_heap() function:
backed_heap allocate_linear_backed_heap(heap meta, id_heap physical)The first parameter corresponds with the heap that is used for bitmap allocation. The second parameter corresponds with the id_heap for the physical memory allocation. The function returns a backed_heap structure. During the allocation of the linear-backed heap, the whole physical heap is mapped by relying on the function linear_backed_init_maps(). This function iterates through the phys id heap ranges and adds the required mappings. The physical memory is mapped at a fixed offset for all memory supported by the linear backed heap. This is an advantage over the page-backed heap because a lookup within page table memory is not necessary.
The linear_backed_alloc() function allocates size bytes:
static u64 linear_backed_alloc(heap h, bytes size)This function returns the physical address of the chunk.
The linear_backed_alloc_map() allocates size bytes and maps it. The function returns the physical address of the new allocation at phys:
static void *linear_backed_alloc_map(backed_heap bh, bytes len, u64 *phys)Releasing
The deallocation is done by using the linear_backed_dealloc() function:
static void linear_backed_dealloc(heap h, u64 x, bytes size)The linear_backed_dealloc_unmap() function deallocates and unmaps a chunk of memory of len bytes which is located at the *virt virtual address and the phys physical address:
static void linear_backed_dealloc_unmap(backed_heap bh, void *virt, u64 phys, bytes len)